
This is a discussion of the kernel implementation and how it might function internally.
Data Structures
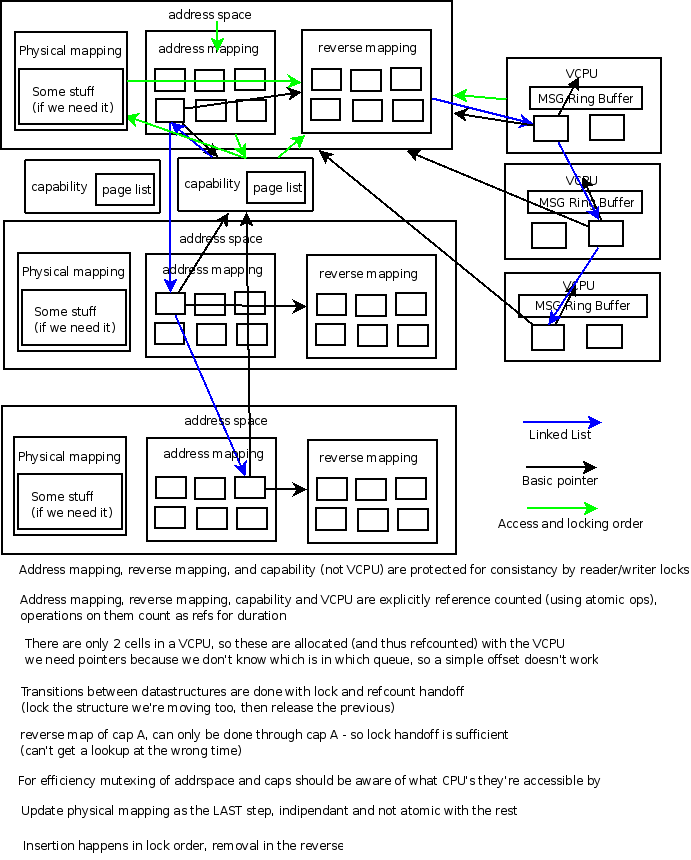
-
Address Space
-
Address mapping - AVL Tree
- An Address space is fundamentally a dictionary which maps address to capabilities.
- Due to hard realtime requirements amortized algorithms are a poor choice (this rules out hash tables and scape-goat trees)
- We cannot beat log(n) lookup amortized time (hash tables must assume a size to beat this). So we probably want a tree structure.
- Since we are searching far more often than inserting we probably want an AVL tree
-
Actual physical memory mapping - Abstract API
- At some point the Address mapping has to actually be put on the hardware. This is architecture specific.
- Many architectures do not have a complete mapping in hardware, and require the kernel to have the mapping available on a page-fault.
- A complete x86 style hardware address mapping eats a lot of memory
- Building a complete mapping on the fly is slow
- On x86 style hardware we can just use a physical mapping that directly mirrors the Address mapping. It's a bit of overhead, but the capability structures were necessary anyway. Additionally if we run low on memory and are willing to take a speed hit we can start dumping page tables and fault load them back in. I'm not sure if this is a good idea in practice though.
- On systems like PowerPC we can simply load the few things necissary directly out of the Address mapping dynamically
- Internal kernel APIs used here should understand BOTH, The physical mapping is exactly the boundary for architecture specific code
-
VCPU mapping - Doubly Linked List
- When an event fires in address space, all assocated VCPU's need to be notified.
- This structure will be removed from and added to, and walked, but never searched
- logical structure is a doubly linked list
- Note - If we cache the kernel page of each VCPU we can probably avoid a huge portion of the address space lookups.
-
Address mapping - AVL Tree
-
Capability
-
Dict of address spaces - Doubly Linked List
- A capability must store every address space it is a part of, so that it can be revoked quickly.
- This structure will be walked, but never searched.
- Requires fast removal when we already know the address space
- Logical answer is a doubley linked list
-
List of events - Doubly Linked List
- We need a way to ensure in-flight events transfering this cap don't try and dereference pointers to this cap.
- This structure has frequent remove and insertion
- This structure is never searched, only walked
-
dict of pages - Doubly Linked List (Maybe RB-Tree?)
- A memory capability contains a number of physical pages.
- This mapping requires knowing the order the pages go in virtual space.
- searching through pages is rarely important (we expect capability splits to be quite rare).
- This can probably be a link-list, though if splits are common benchmarking should be done and possibly an RB tree or similar structure i should be used.
-
Event queue - Singly Linked List
- This is just a queue of events. Events are allocated from a pool for efficiency.
- events containing transfers of ownership of capabilities count as owners for the purposes of free'ing and the like. It should be noted that this means the cap cannot be free'd until the event is dequeued. For non-owning cap transmission events we must ensure we don't end up with a dangling pointer when the Cap is free'd.
-
Dict of address spaces - Doubly Linked List
Freeing data structures
-
Capability
- Capabilities have a single owner, when that owner drops the reference the capability is gone.
- valid owners are address spaces and in-flight messages which are transfering ownership of the cap.
- if a capability is free'd so must all of it's associated data. This means entire address spaces. As a result free-ing a capability can set off an enourmous chain of events, conceivably freeing every cap in the system. This is a feature since it's part of the security model.
- a capability must also ensure that all pointers to it from in-flight events are somehow repaired before the cap disapepars.
- Bear in mind that an address space can be it's own owner, this is legitamate. It's a circular reference, but thats fine. dropping the cap from that address space will free the address space, just like normal.
-
VCPU
- a VCPU has an associated address space which it will run in when an event is fired
- Consider revocation of this address space. The VCPU should fault in userland when It's address space is revoked.
- The critical point is that revocation from of an address space must change data in any associated VCPU as notification so it doesn't have a dangling pointer.
- a VCPU has an associated address space which will trigger events in the VCPU
- Consider revocation of this address space. The VCPU should recieve the revocation event.
- a VCPU sometimes needs to store the full machine state, initially this can be done by preallocating enough memory. If it turns out this case is rare enough (I.E. users rarely have preemption disabled "too long") than the memory can be allocated lazilly, and possibly freed again.
Freeing order
So freeing should occur thusly-
Capability
- check if already free'ing, if so return
- Mark capability as free'ing
- Walk the list of Address spaces that we belong too
- For each address space find the capability and remove it
- Walk the list of in-flight events containing this capability
- For each, point the event at a dummy value
- Free all data associated with the capability (that means if this is an address space cap, free the address space)
-
Address Space
- Mark address space as free'ing
- Walk the notification list of VCPU's
- For each one send a notification to that VCPU that we're gone
- Walk the running_in list of VCPU's
- For each one change the VCPU's "running_in" to a dummy value
- Walk the list of capabilities
- For each capability, if we are owner, free it
-
VCPU
- Go to the address space we're running_in, and romove ourselves from the "running_in" list
- Go to the address space we're getting events from and remove ourselves from the notification list
Preemptability
No point in bothering. We should spend so little time in kernel that it's just not worth the hassle. We DO need to deal with suddenly needing to swap in user pages so the kernel can write to them. I was figuring on using transactional semantics and simply starting read from disk, and rolling back kernel state to just after the user entered kernel land. We then go do something else until the interrupt or whatever tells us the data is ready.
SMP support
This is messy, no getting around it. We have fairly complex, recursive, in kernel structures that are going to need a lot of complex locking. There are fundamentally 2 approaches to this problem
- 1) We simply lock the heck out of everything
- 2) We tie various structures to particular processors, and cross-call to modify them.
The advantage to #1 is that we only have to think about atomicity and not where things live. The disadvantage is high lock contention. The advantage of #2 is low lock contention, but concievably a lot of high-latency cross calls.
So far I've been planning to write #1 for the first shot, simply because I know more about how to write it, it's somewhat simpler, and it's not known that #2 would get better performance. #2 also requires the idea of "data migration" for load balancing purposes, which adds some complexity to the whole system. It's hard to tell where a capability should live for example, or an address-space with multiple threads running in it. I would be VERY interested to hear arguments as to why #2 is better in the case of this design, and even more interested to hear how it might be implemented.